Safari for Windows
If Mac released Safari for Windows and it became popular then how many web sites would suddenly need a re-design? How many would need to tweak their CSS and XHTML? More than a few, I would say. Mass re-designs would shake up SERPs.
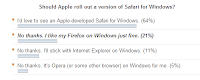 ZDNet are running a poll on the issue and although it is early days yet (early days favour the Windows masses due to mathematical distribution curves) the idea of Safari for Windows clearly has a lot of support. Mind you, Mac have just announced the iPhone and everyone loves Mac just now. It's the fashion. Mock Mac? No. Not me. You must have been thinking of someone else.
ZDNet are running a poll on the issue and although it is early days yet (early days favour the Windows masses due to mathematical distribution curves) the idea of Safari for Windows clearly has a lot of support. Mind you, Mac have just announced the iPhone and everyone loves Mac just now. It's the fashion. Mock Mac? No. Not me. You must have been thinking of someone else.
If we do have a three-way field in the browser race; Internet Explorer, Firefox and Safari (or a four-way if I'm kind enough to remember Opera (and at least one Organic Search Manager at work is a fan)) then we're likely to see more web sites employ user-agent detection scripts.
User-agent detection is always risky. Google (Yahoo and Live Search) need to be sure that the web site they are seeing is the same web site that everyone else is seeing. If user-agent detection is place than there is doubt. Sometimes some features simply do not work on other browsers and an alternative presentation is necessary. At that point you are showing a different version of the web site to different user-agents.
In fact, ZDNet's Mary Jo Foley has dug up some obscure suggestion that Mozilla is expecting Mac to bring Safari to Windows. Could they? Yes. Would they? That's harder to answer.
This is not a problem which the search engines would struggle to serve. Googlebot already visits sites pretending to be Internet Explorer in order to try and catch cloakers out. That's one of the reasons why user-agent cloaking is scoffed at.
If the web was viewed by a competitive range of browsers and user-agent detection became commonplace then the search engines would have to respond by spoofing their own user-agent more often.
All this comes at a time when the SEO community are discussing whether Google is/whether Google could parse CSS. Google is. Google can. It strikes me as madness to suggest that Google could not cope with CSS. Of course Google can cope with mere CSS! Of course! It's just text. It's simply the case that (and we're back to the distribution curves) that CSS checking has not been worth Google's effort. For all the benefits that CSS spidering would bring the cost would be too great. It's a numbers game.
CSS continues to grow in popularity, so hidden or conditionally visible text becomes more and more common, and it is therefore not a surprise to find that Google is taking stock of things. It could well be the case that Google concludes this look at CSS and decides it is still not worth the effort. This would not be unheard of. In 2004 a test Googlebot was seen scooping up .js files. We didn't see this bot back in a hurry.
Google can cope with JavaScript too. For heavens sake, spammers can defeat captchas, of course Google can cope with JavaScript and CSS. Finding a way through captchas is worth the spammer's while. Picking through JavaScript may not be worth Google's while.
... unless, that is, alternative browsers like Safari become more popular and JavaScript based user-agent detection becomes the norm.
 ZDNet are running a poll on the issue and although it is early days yet (early days favour the Windows masses due to mathematical distribution curves) the idea of Safari for Windows clearly has a lot of support. Mind you, Mac have just announced the iPhone and everyone loves Mac just now. It's the fashion. Mock Mac? No. Not me. You must have been thinking of someone else.
ZDNet are running a poll on the issue and although it is early days yet (early days favour the Windows masses due to mathematical distribution curves) the idea of Safari for Windows clearly has a lot of support. Mind you, Mac have just announced the iPhone and everyone loves Mac just now. It's the fashion. Mock Mac? No. Not me. You must have been thinking of someone else.If we do have a three-way field in the browser race; Internet Explorer, Firefox and Safari (or a four-way if I'm kind enough to remember Opera (and at least one Organic Search Manager at work is a fan)) then we're likely to see more web sites employ user-agent detection scripts.
User-agent detection is always risky. Google (Yahoo and Live Search) need to be sure that the web site they are seeing is the same web site that everyone else is seeing. If user-agent detection is place than there is doubt. Sometimes some features simply do not work on other browsers and an alternative presentation is necessary. At that point you are showing a different version of the web site to different user-agents.
In fact, ZDNet's Mary Jo Foley has dug up some obscure suggestion that Mozilla is expecting Mac to bring Safari to Windows. Could they? Yes. Would they? That's harder to answer.
This is not a problem which the search engines would struggle to serve. Googlebot already visits sites pretending to be Internet Explorer in order to try and catch cloakers out. That's one of the reasons why user-agent cloaking is scoffed at.
If the web was viewed by a competitive range of browsers and user-agent detection became commonplace then the search engines would have to respond by spoofing their own user-agent more often.
All this comes at a time when the SEO community are discussing whether Google is/whether Google could parse CSS. Google is. Google can. It strikes me as madness to suggest that Google could not cope with CSS. Of course Google can cope with mere CSS! Of course! It's just text. It's simply the case that (and we're back to the distribution curves) that CSS checking has not been worth Google's effort. For all the benefits that CSS spidering would bring the cost would be too great. It's a numbers game.
CSS continues to grow in popularity, so hidden or conditionally visible text becomes more and more common, and it is therefore not a surprise to find that Google is taking stock of things. It could well be the case that Google concludes this look at CSS and decides it is still not worth the effort. This would not be unheard of. In 2004 a test Googlebot was seen scooping up .js files. We didn't see this bot back in a hurry.
Google can cope with JavaScript too. For heavens sake, spammers can defeat captchas, of course Google can cope with JavaScript and CSS. Finding a way through captchas is worth the spammer's while. Picking through JavaScript may not be worth Google's while.
... unless, that is, alternative browsers like Safari become more popular and JavaScript based user-agent detection becomes the norm.

Comments